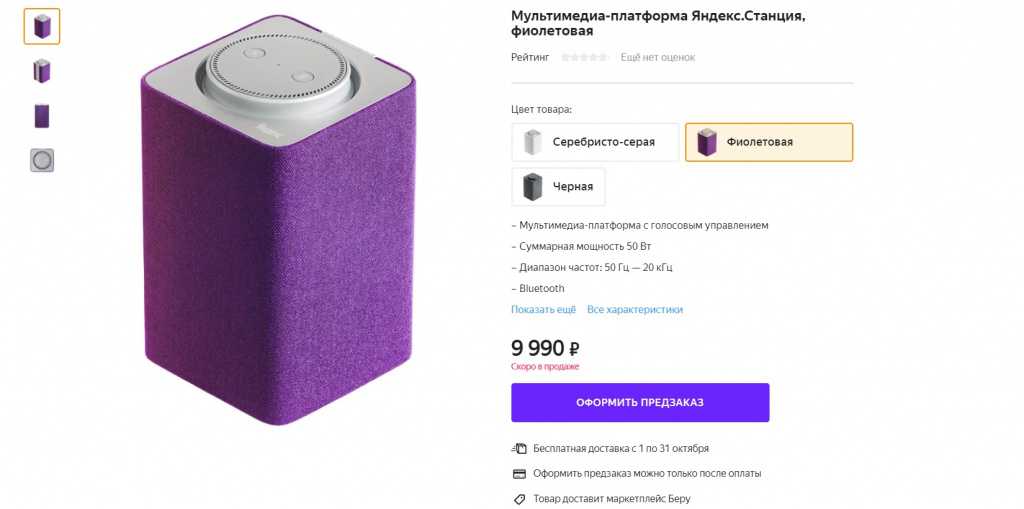
Колонка алиса функции выполняет какие
Возможности умных колонок с Алисой
Возможности Яндекс.Станции нельзя назвать безграничными, но колонка умеет действительно многое. В статье приведены возможные сценарии реального использования устройства.
Интеллектуальный голосовой помощник
В первую очередь нужно отметить, что в Яндекс.Станцию интегрирован голосовой помощник Алиса. Таким образом, колонка поддерживает практически все функции Алисы:
- Информационные запросы. Поиск информации в Интернете c учетом контекста
- Актуальный прогноз погоды и курсы валют, в том числе криптовалют
- Актуальная дорожная ситуация
- Чтение новостной ленты
- Поиск заведений поблизости
- Простые математические операции
- Управление будильником
- Создание напоминания
- Установка таймера на n минут
- Чтение сказки или песни, рассказ анекдота
Работа с музыкой
Яндекс. Станция является мультимедийным устройством. В отличие от обычных колонок, она не просто воспроизводит аудиосигнал, но и поддерживает полноценное управление музыкой:
- Воспроизведение музыкальной композиции: конкретной, определенного автора, определенного жанра или случайной
- Остановка и возобновление воспроизведения
- Перемотка вперед или назад на n секунд или n минут
Работа с видеоконтентом
Более того, интеллектуальная колонка от Яндекс поддерживает подключение к телевизору или монитору по HDMI и умеет управлять видеоконтентом:
Выбор необходимого фильма в каталоге (которые совмещает контент из ivi.ru, Кинопоиска и Amediateka)
Воспроизведение и постановка на паузу
Перемотка вперед или назад на n секунд или n минут
Расширенные возможности
Самое интересное - интеграция с сервисом “Яндекс.Диалоги”. Данный сервис позволяет сторонним разработчикам и крупным компаниям создавать отдельные навыки с голосовым интерфейсом для Алисы. Это позволяет значительно расширить возможности устройства. Яндекс.Станцию можно будет использовать для вызова такси, заказа пиццы или проведения платежей в Сбербанке. На данный момент уже поддерживаются чаты от следующих компаний:
Это позволяет значительно расширить возможности устройства. Яндекс.Станцию можно будет использовать для вызова такси, заказа пиццы или проведения платежей в Сбербанке. На данный момент уже поддерживаются чаты от следующих компаний:
- Папа Джонс - заказ пиццы
- S7 Airlines - приобретение билетов авиакомпании
- Мегафон - различные сервисы
- Reebok - товары для спорта
- Утконос - заказ продуктов питания
- Сбербанк - различные сервисы
- Макдональдс - фаст-фуд
- HeadHunter - поиск работы
- Skyeng - изучение английского языка
Чтобы оценить полные возможности Яндекс.Станции, пользователю понадобится учетная запись яндекса. Активации персонального помощника происходит голосом - достаточно обратиться к Алисе по имени.
Управление умным домом
На данный момент умная колонка поддерживает управление устройствами "Умный дом" (IoT устройства). Разработчики регулярно добавляют новые модули и расширяют поддержку оборудования.
Станция Макс с Алисой
удивит трехполосным звуком, покажет видео в 4K, включит умную лампу...
Умная колонка с Алисой
Разбудит утром, расскажет рецепт блюда, включит любимую музыку, озвучит прогноз погоды и дорожную обстановку
09 Июня 2018 | 82091
Характер Алисы по цвету колонки
Умные вещи
Рынок умных звуковых устройств в России развивается стремительно. Smart колонки от компании Яндекс вписываются в общий стиль жизни пользователей, соответствуют требованиям. Новая мини-модель — Станция Лайт. Появилась особенность – характер умной Алисы по цвету колонки. Производитель разработал 6 цветов характеров.
Цвета Алисы
Алиса подстраивается под предпочтения владельца. Каждый вариант цвета проявляет свои особенности характера. Модель по-разному отвечает на вопросы, разные предпочтения в музыке.
Цвета и характеры колонок:
- Бежевая. Добрая, спокойная. Предпочитает приятных людей, хорошие книги, интересные фильмы.
- Желтая. Индивидуальная, яркая, хочет отличаться от принятых стандартов.
- Бирюзовая. Нежная, тонкая, любит шум дождя, звуки природы и голос владельца.
- Розовая. Верит в волшебство, любит сказки. Романтичная, влюбленная.
- Красная. Предпочитает активный образ жизни. Хорошо сочетается с интерьером.
- Фиолетовый цвет. Для шумных дружеских компаний. Ритмичная, веселая.
Понять музыкальные вкусы и уникальные черты характера можно одним вопросом – «Алиса, включи мне классную музыку».
Подробности о колонке
Яндекс.Станция мини сделана в форме миниатюрной шайбы с логотипом. Комплектность: адаптер на 7,5 Вт, USB-кабель, документ с инструкцией, фирменные наклейки. Подарок — 3-х месячная подписка Яндекс.Плюс. Она начинает действовать с момента регистрации умной колонки.
Инструкция, формально, не нужна. При включении голосового помощника, независимо от характера и цвета, Алиса активизируется, поприветствует владельца, расскажет, что нужно делать для настройки устройства.
Станция работает при использовании провода. Автономия предусмотрена с пауэрбанком. Без провода блока питания колонка не активна.
Узнайте больше: Чем отличается Алиса Лайт от Мини
Пошаговая настройка
Колонка полезна там, где есть интернет-соединение. Без него станция будет уведомлять о его отсутствии. Главная часть умного устройства – ассистент Алиса, которая может помочь.
Настройка:
- Запуск Wi-Fi. Можно раздать с телефона, но не с того, по которому будет производиться настройка.
- Загрузка приложения.
- Вход в свой аккаунт.
- Проиграть звуковой код.
Данные:
- гарантия – 1 год;
- страна – Китай;
- срок службы — 2 года;
- модуль блютуз — 5.0;
- умный дом;
- пульт дистанционного управления;
- вес – 200 гр;
- размеры – 90*45*90 м .
При походе в гости с колонкой, нужно будет проходить процедуру настройки заново, домашняя сеть также не будет распознана.
К сети Wi-Fi в гостинице или ресторане не удастся подключиться, так как необходимо перейти на сайт и ввести номер телефона.
Взаимодействие со станцией
Алиса с любым характером и цветом радостно примет участие в общении. Она знает все о погоде, о пробках в городе, новостях в мире. Можно задать неожиданный вопрос, получить на него ответ. Она распознает голос, даже если спросить из другой комнаты или на фоне музыки.
Помощница запоминает голос собственного владельца. Она может называть его по имени или забавным прозвищем.
В устройство встроен TOF-датчик. Технология позволяет использовать для общения жесты. Язык жестов:
- Прибавить громкость – плавное поднятие руки вверх.
- Убавить громкость – плавное опускание руки вниз.
- Оперативное выключение – накрыть колонку ладонью.
Поддерживается синтезатор. Можно выбрать любой инструмент, играть на нем жестами. Функция корректно работает в темное время.
Яркие и стильные компактные колонки Станции версии Лайт выполняют те же команды, что стандартные устройства. По мощности они превосходят дорогие варианты – 5 Вт. Модель не имеет защиты от воды, не следует трогать ее мокрыми руками.
По мощности они превосходят дорогие варианты – 5 Вт. Модель не имеет защиты от воды, не следует трогать ее мокрыми руками.
Пользователям перед покупкой умной колонки Алисы рекомендуется присмотреться сначала к своему характеру, чтобы правильно выбрать цвет Яндекс Станции.
Меткиалисаумный домСтатистические и математические функции с кадрами данных Spark
Мы представили кадры данных в Apache Spark 1.3, чтобы упростить использование Apache Spark. Вдохновленные фреймами данных в R и Python, DataFrames в Spark предоставляют API, похожий на инструменты обработки данных с одним узлом, с которыми уже знакомы специалисты по данным. Статистика является важной частью повседневной науки о данных. Мы рады сообщить об улучшенной поддержке статистических и математических функций в предстоящем выпуске 1.4.
В этом сообщении блога мы рассмотрим некоторые важные функции, в том числе:
- Генерация случайных данных
- Сводная и описательная статистика
- Выборочная ковариация и корреляция
- Перекрестная таблица (также известная как таблица сопряженности)
- Часто встречающиеся элементы
- Математические функции 8 90 Однако аналогичные API существуют и для пользователей Scala и Java.

1. Генерация случайных данных
Генерация случайных данных полезна для тестирования существующих алгоритмов и реализации рандомизированных алгоритмов, таких как случайная проекция. Мы предоставляем методы в sql.functions для создания столбцов, содержащих i.i.d. значения, взятые из распределения, например, равномерное (
рандов) и стандартное нормальное (рандов).В [1]: из pyspark.sql.functions импортировать rand, randn В [2]: # Создать
2. Сводная и описательная статистика
Первая операция, которую необходимо выполнить после импорта данных, — это получить представление о том, как они выглядят. Для числовых столбцов знание описательной сводной статистики может сильно помочь в понимании распределения ваших данных. Функция
описатьвозвращает DataFrame, содержащий такую информацию, как количество ненулевых записей (количество), среднее значение, стандартное отклонение, а также минимальное и максимальное значение для каждого числового столбца.
В [1]: из pyspark.sql.functions импортировать rand, randn В [2]: # Немного другой способ генерации двух случайных столбцов В [3]: df = sqlContext.range(0, 10).withColumn('uniform', rand(seed=10)).withColumn('normal', randn(seed=27)) В [4]: df.describe().show() +-------+--------------------------------+-----+-- ------------------+ |резюме| идентификатор | униформа| нормальный| +-------+--------------------------------+-----+-- ------------------+ | количество | 10| 10| 10| | означает | 4,5 | 0,5215336029384192|-0,01309370117407197| | стандартное отклонение|2.87228132326 - | 0,229328162820653| 0,5756058014772729| | мин| 0|0,19657711634539565| -0,7195024130068081| | макс | 9| 0,9970412477032209| 1.0
- 6472044518| +-------+--------------------------------+-----+-- ------------------+
Если у вас есть DataFrame с большим количеством столбцов, вы также можете выполнить описание для подмножества столбцов:
В [4]: df.describe('uniform', 'normal').show() +-------+---------------------------------+------+ |резюме| униформа| нормальный| +-------+---------------------------------+------+ | количество | 10| 10| | означает | 0,5215336029384192|-0,01309370117407197| | стандартное отклонение | 0,229328162820653| 0,5756058014772729| | мин|0,19657711634539565| -0,7195024130068081| | макс | 0,9970412477032209| 1. 0
0 - 6472044518| +-------+---------------------------------+------+
Конечно, хотя описание хорошо подходит для быстрого исследовательского анализа данных, вы также можете управлять списком описательной статистики и столбцами, к которым они применяются, используя обычный выбор в DataFrame:
В [5]: из pyspark.sql.functions среднее значение импорта, мин, макс В [6]: df.select([mean('uniform'), min('uniform'), max('uniform')]).show() +------------------+-------------------+----------- --------+ | СРЕДНИЙ (равномерный) | МИН(равномерный)| МАКС(униформа)| +------------------+-------------------+----------- --------+ |0,5215336029384192|0,19657711634539565|0,9970412477032209| +------------------+-------------------+----------- --------+3. Выборочная ковариация и корреляция
Ковариация — это мера того, как две переменные изменяются по отношению друг к другу. Положительное число будет означать, что при увеличении одной переменной увеличивается и другая.
 Отрицательное число будет означать, что по мере увеличения одной переменной другая переменная имеет тенденцию к уменьшению. Выборочная ковариация двух столбцов DataFrame может быть рассчитана следующим образом:
Отрицательное число будет означать, что по мере увеличения одной переменной другая переменная имеет тенденцию к уменьшению. Выборочная ковариация двух столбцов DataFrame может быть рассчитана следующим образом: В [1]: из pyspark.sql.functions импортировать rand В [2]: df = sqlContext.range(0, 10).withColumn('rand1', rand(seed=10)).withColumn('rand2', rand(seed=27)) В [3]: df.stat.cov('rand1', 'rand2') Выход[3]: 0,009908130446217347 В [4]: df.stat.cov('id', 'id') Выход[4]: 9.166666666666666Как видно из вышеизложенного, ковариация двух случайно сгенерированных столбцов близка к нулю, в то время как ковариация столбца id с самим собой очень высока.
Значение ковариации 9.17 может быть трудно интерпретировать. Корреляция — это нормализованная мера ковариации, которую легче понять, поскольку она обеспечивает количественные измерения статистической зависимости между двумя случайными величинами.
В [5]: df.stat.corr('rand1', 'rand2') Выход[5]: 0,14938694513735398 В [6]: df. stat.corr('id', 'id') Выход[6]: 1.0
stat.corr('id', 'id') Выход[6]: 1.0 В приведенном выше примере id идеально коррелирует сам с собой, в то время как два случайно сгенерированных столбца имеют низкое значение корреляции.
4. Перекрестная таблица (таблица непредвиденных обстоятельств)
Перекрестная таблица предоставляет таблицу частотного распределения набора переменных. Кросс-табулирование — это мощный инструмент в статистике, который используется для наблюдения за статистической значимостью (или независимостью) переменных. В Spark 1.4 пользователи смогут составлять кросс-таблицы для двух столбцов DataFrame, чтобы получить количество различных пар, наблюдаемых в этих столбцах. Вот пример того, как использовать перекрестную таблицу для получения таблицы непредвиденных обстоятельств.
В [1]: # Создать DataFrame с двумя столбцами (имя, элемент) В [2]: имена = ["Алиса", "Боб", "Майк"] В [3]: items = ["молоко", "хлеб", "масло", "яблоки", "апельсины"] В [4]: df = sqlContext.createDataFrame([(names[i % 3], items[i % 5]) for i in range(100)], ["name", "item"]) В [5]: # Взгляните на первые 10 строк.
 В [6]: df.show(10) +-----+-------+ | имя| пункт| +-----+-------+ |Алиса| молоко| | Боб| хлеб | | Майк| сливочное масло| |Алиса| яблоки| | Боб|апельсины| | Майк| молоко| |Алиса| хлеб | | Боб| сливочное масло| | Майк| яблоки| |Алиса|апельсины| +-----+-------+ В [7]: df.stat.crosstab("name", "item").show() +---------+----+-----+------+------+-------+ |name_item|молоко|хлеб|яблоки|масло|апельсины| +---------+----+-----+------+------+-------+ | Боб| 6| 7| 7| 6| 7| | Майк| 7| 6| 7| 7| 6| | Алиса| 7| 7| 6| 7| 7| +---------+----+-----+------+------+-------+
В [6]: df.show(10) +-----+-------+ | имя| пункт| +-----+-------+ |Алиса| молоко| | Боб| хлеб | | Майк| сливочное масло| |Алиса| яблоки| | Боб|апельсины| | Майк| молоко| |Алиса| хлеб | | Боб| сливочное масло| | Майк| яблоки| |Алиса|апельсины| +-----+-------+ В [7]: df.stat.crosstab("name", "item").show() +---------+----+-----+------+------+-------+ |name_item|молоко|хлеб|яблоки|масло|апельсины| +---------+----+-----+------+------+-------+ | Боб| 6| 7| 7| 6| 7| | Майк| 7| 6| 7| 7| 6| | Алиса| 7| 7| 6| 7| 7| +---------+----+-----+------+------+-------+ Важно помнить, что количество столбцов, по которым мы запускаем кросс-таблицу, не может быть слишком большим. Другими словами, количество отдельных «имени» и «предмета» не может быть слишком большим. Только представьте, если «элемент» содержит 1 миллиард различных записей: как бы вы разместили эту таблицу на своем экране?!
5. Часто встречающиеся элементы
Выяснение того, какие элементы являются частыми в каждом столбце, может быть очень полезным для понимания набора данных.
 В Spark 1.4 пользователи смогут находить часто встречающиеся элементы для набора столбцов с помощью DataFrames. Мы реализовали однопроходный алгоритм, предложенный Karp et al. Это быстрый приблизительный алгоритм, который всегда возвращает все часто встречающиеся элементы, которые появляются в заданной пользователем минимальной доле строк. Обратите внимание, что результат может содержать ложные срабатывания, т. е. нечастые элементы.
В Spark 1.4 пользователи смогут находить часто встречающиеся элементы для набора столбцов с помощью DataFrames. Мы реализовали однопроходный алгоритм, предложенный Karp et al. Это быстрый приблизительный алгоритм, который всегда возвращает все часто встречающиеся элементы, которые появляются в заданной пользователем минимальной доле строк. Обратите внимание, что результат может содержать ложные срабатывания, т. е. нечастые элементы. В [1]: df = sqlContext.createDataFrame([(1, 2, 3) if i % 2 == 0 else (i, 2 * i, i % 4) для i в диапазоне (100)], [ "а", "б", "в"]) В [2]: df.show(10) +-+--+-+ |а| б|в| +-+--+-+ |1| 2|3| |1| 2|1| |1| 2|3| |3| 6|3| |1| 2|3| |5|10|1| |1| 2|3| |7|14|3| |1| 2|3| |9|18|1| +-+--+-+ В [3]: freq = df.stat.freqItems(["a", "b", "c"], 0,4)
Учитывая приведенный выше DataFrame, следующий код находит часто встречающиеся элементы, которые отображаются в 40% случаев для каждого столбца:
В [4]: freq.collect()[0] Out[4]: Строка (a_freqItems=[11, 1], b_freqItems=[2, 22], c_freqItems=[1, 3])
Как видите, «11» и «1» — наиболее часто встречающиеся значения для столбца «а».
 Вы также можете найти часто встречающиеся элементы для комбинаций столбцов, создав составной столбец с помощью функции struct:
Вы также можете найти часто встречающиеся элементы для комбинаций столбцов, создав составной столбец с помощью функции struct: В [5]: из структуры импорта pyspark.sql.functions В [6]: freq = df.withColumn('ab', struct('a', 'b')).stat.freqItems(['ab'], 0.4) В [7]: freq.collect()[0] Out[7]: Строка (ab_freqItems = [Строка (a = 11, b = 22), Строка (a = 1, b = 2)])В приведенном выше примере комбинация «a=11 и b=22» и «a=1 и b=2» часто встречается в этом наборе данных. Обратите внимание, что «a=11 и b=22» является ложным срабатыванием.
6. Математические функции
В Spark 1.4 также добавлен набор математических функций. Пользователи могут легко применять их к своим столбцам. Список поддерживаемых математических функций взят из этого файла (мы также опубликуем готовую документацию после выхода версии 1.4). Входные данные должны быть функциями столбцов, которые принимают один аргумент, например
318| 25,99427062175921| 1,0 | | 0,873869321369476| 50.06902396043238|0.9999999999999999| | 0,9970412477032209| 57.12625549385224| 1,0 | | 0,19657711634539565| 11.26303911544332|1.0000000000000002| | 0,9632338825504894| 55.18923615414307| 1,0 | +----------------------------------+----+---------- ---------+cos,sin,floor,ceil. Для функций, принимающих на вход два аргумента, например 92| +----------------------------------+----+---------- ---------+ | 0,7224977951905031| 41.39607437192317| 1,0 | | 0,3312021111290707|18,976483133518624|0,99999999999999999| | 0,2953174992603351|16,920446323975014| 1,0 | |0,018326130186194667| 1.050009914476252|0.9999999999999999| | 0,3163135293051941|18,123430232075304| 1,0 | | 0,45368560
Для функций, принимающих на вход два аргумента, например 92| +----------------------------------+----+---------- ---------+ | 0,7224977951905031| 41.39607437192317| 1,0 | | 0,3312021111290707|18,976483133518624|0,99999999999999999| | 0,2953174992603351|16,920446323975014| 1,0 | |0,018326130186194667| 1.050009914476252|0.9999999999999999| | 0,3163135293051941|18,123430232075304| 1,0 | | 0,45368560Что дальше?
Все функции, описанные в этом сообщении блога, будут доступны в Spark 1.4 для Python, Scala и Java, который будет выпущен в ближайшие несколько дней. Если вам не терпится, вы также можете сами собрать Spark из ветки релиза 1.4: https://github.com/apache/spark/tree/branch-1.
 4
4 Поддержка статистики для DataFrames будет расширяться за счет лучшей интеграции со Spark MLlib в будущих выпусках. Использование существующего пакета статистики в MLlib, поддержка выбора функций в конвейерах, корреляция Спирмена, ранжирование и агрегатные функции для ковариации и корреляции.
В конце сообщения в блоге мы также хотели бы поблагодарить Дэвиса Лю, Адриана Ванга и остальных участников сообщества Spark за реализацию этих функций.
Ссылка на модель данных· Документация ALICE O2
Модель данных ALICE O2 представляет собой набор таблиц. Каждую таблицу можно рассматривать как набор объектов, где каждый столбец представляет свойство объектов, а каждая строка является объектом. Когда пользователи пишут свой анализ, они должны предоставить как минимум две вещи: запрос, который выбирает строки одной или нескольких таблиц, и функцию, которая вызывается по результатам запроса. При указании запроса пользователи могут выполнять между собой типичные операции с базой данных.
 Например, они могут выбирать только строки, соответствующие заданному запросу, или они могут поместить две таблицы одну рядом с другой и выбрать строки результирующей таблицы в так называемом «объединении».
Например, они могут выбирать только строки, соответствующие заданному запросу, или они могут поместить две таблицы одну рядом с другой и выбрать строки результирующей таблицы в так называемом «объединении». Таблицы могут быть прочитаны из входных файлов AO2D файлов или могут быть созданы задачами. Для создания некоторых таблиц с часто используемыми величинами существует набор предопределенных вспомогательных задач, которые можно включить в рабочие процессы пользовательского анализа для создания таблиц с часто используемой информацией.
Модель данных также предоставляет набор предопределенных объединений и итераторов.
Связи таблиц
Информация, содержащаяся в разных таблицах, может быть связана. Например. трек принадлежит данному столкновению, или сигналы в детекторах FIT или Zdc принадлежат пересечению связки.
Следовательно, зависимые таблицы должны содержать индекс, указывающий на определенную строку главной таблицы. Для этого зависимая таблица (например, таблица Tracks) имеет столбец индекса [master]Id (в данном случае CollisionsId), который указывает на связанную информацию в мастере таблицы.
 См. также, например. master=BC и зависимые=CaloTriggers и многие другие.
См. также, например. master=BC и зависимые=CaloTriggers и многие другие. Цель
Для каждого индекса в таблице существует метод получения соответствующего объекта. Например в таблице aod::Tracks есть индекс CollisionId. Итак, если у вас есть объект aod::Track с именем track, вы можете напрямую получить доступ к столкновению этого трека, вызвав track.collision(). Вы также можете проверить, прежде чем сделать, чтобы интересующий вас трек имел коллизию, используя шаблонную функцию .has_smthg() , в этом примере используется track.has_collision(), которая возвращает логическое значение . Тип объекта track.collision() — o2::aod::Collision. Это верно для каждого индекса в каждой таблице, поэтому вызов, например, Collision.bc() дает вам bc коллизии, над которой вы работаете. Затем вы можете вызвать, например, Collision.bc().globalBC() .
Примечание
Имейте в виду, что таблицы могут быть объединены и дополнены дополнительными столбцами.

В списках таблиц на следующих страницах буква в скобках после имени таблицы указывает тип таблицы:
- E: расширенный стол
- I: индексная таблица
- иначе: обычная таблица
Аналогично для столбцов:
- D: динамический столбец, вычисляемый при запросе столбца, не кэшируемый, поэтому его следует избегать в циклах
- E: столбец выражения, вычисляемый при запросе таблицы только один раз и поэтому может использоваться в циклах
- GI: глобальный индекс
- I: столбец индекса
- SI: столбец автоиндекса
- SLI: столбец индекса среза
- SSLI: столбец индекса собственного среза
- SAI: столбец индекса собственного массива
- иначе: обычный столбец
Вы просматриваете:
- документы
- модель данных
- README.